滚雪球吧 - 让财富的雪球滚起来
滚雪球吧 - 让财富的雪球滚起来甚至还可以实时在线教你打游戏了。
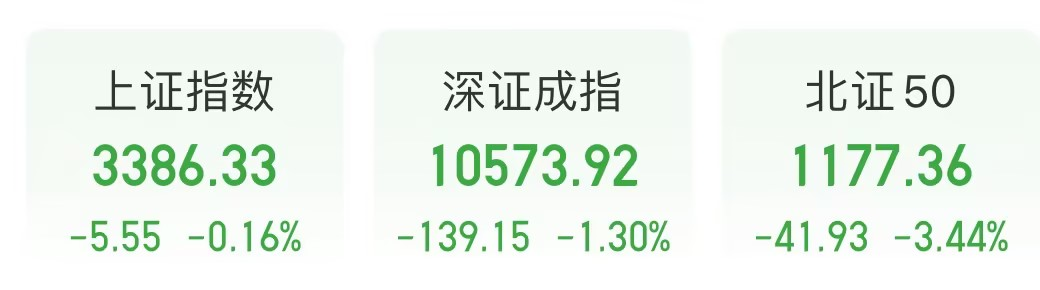
2024 年走到年底,似乎 AI 大厂们集体又决定搞点事情了。
在 OpenAI 宣布连发 12 天更新后,Google 选择 12 月 11 日深夜(在 OpenAI 发布更新之前),发布新模型 Gemini 2.0。
在多次发布被 OpenAI 精准狙击后,Google 今夜扳回一局,发布了 Gemini 2.0,直指 Agent 使用,一个 OpenAI 至今没有明确公开布局的领域——之前有消息称,OpenAI 将在明年推出使用电脑的 Agent。
Agent 功能,也称为智能体功能,通常指的是 AI 能够感知环境、执行任务并在一定程度上独立做出决策的能力,也就是能更自动化完成任务的功能。
此次 Google 似乎赌对了。OpenAI 凌晨两点的发布,主要宣布了和 Apple Intelligence 的合作,一个普遍被期待能与 Agent 能力强相关的合作。不过今夜最终的发布,主要仍然集中于文字生成和视觉智能方面,并没有 Agent 相关的内容。
而 Google,则一次性发布了四个 Agent 相关的功能:
Project Astra,能够在 Gemini 应用中直接调用 Google Lens 和地图功能帮用户解决问题;
Project Mariner(海员项目),Chrome 浏览器的实验性功能,可以通过 提示词直接帮用户浏览网页做任务;
Jules,可以嵌入 GitHub 的编程 Agent,使用自然语言描述问题,就能直接生成可以合并到 GitHub 项目中的代码;
游戏 Agent,能够实时解读屏幕画面,直接在你打游戏的时候通过和你语音交流,给你 AI 打法提示。
虽然此次 Google 发布的功能仍然属于期货范畴,但是仍然十分令人兴奋。我们似乎已经可以洞见 Agent 真正到来的时代,人类生活的一角了。
01
炸裂新 Agent 功能:自己查资料、写代码,教你玩游戏
Google 的新功能建立在新模型 Gemini 2.0 能力之上。
和大部分大模型选择的路线不一样,Google 最早就选择了使用原生多模态的的方式训练模型——OpenAI 到了 GPT-4o 模型才变成原生多模态的模型。
原生多模态模型,是在训练阶段,就将图像、文字、语音甚至视频等多种编码,统一输入给一个模型进行学习。
这样,模型可以在理解了一个「事物」后,更加灵活地利用进行不同模态的生成。
此次 Gemini 2.0,进一步升级了原生多模态能力。模型目前直接拥有了原生的图像生成能力、音频输出能力和原生的工具应用能力。
原生的工具应用能力就和 Agent 的能力高度相关。Google 介绍,除此之外,新体验还来自于多模态推理、长上下文理解、复杂指令遵循和规划、组合函数调用、本地工具使用和降低延迟等方向的改进。
看一下 Google 提出的新功能演示:
Project Mariner 是这个系列中,笔者看起来最惊喜的演示。
主要原因可能是因为相对于其他功能,Google 的 Chrome 浏览器是笔者每天都要使用的工具,也是对工作效率影响最高的工具。而 Google 的这项试验性功能,看起来也不需要对浏览器进行过多的额外配置——只需要用到扩展程序。
Google 很懂地选了一个生产力场景,让 Chrome 打开一个表格(演示里里用的是 Google Docs,不知道这与最终的成功识别是不是有相关性)。
表格里有几个公司的名字。演示者打开 Chrome 的这项试验功能,让 Chrome 自己记住这几个公司名字,去网上查找这些公司的邮箱。(同样的,查找使用的是 Google 搜索,不知道是不是与最后的演示成功相关。)
浏览器自己打开了网页,自己点开每个公司的官网,在找到邮箱地址后,自动记住邮箱地址,关掉网页开始查找下一个公司的邮箱地址。
全程,用户可以在右边栏输入提示词的位置,看到模型目前在如何思考,随时停止自动操作。同时模型只会在前台运行,不会在用户看不到的标签页中运行。
虽然前台运行似乎对用户的时间是一种消耗,但同时也保证了安全性。在这个案例中,也确实提升了生产效率——挨个查找邮箱确实是一件非常没有创造力的工作。
Jules,则让自然语言写代码似乎更近了一步。
在演示中,用户输入了一段非常详细的编程问题的提示词,包括在哪个文件中遇到什么问题,希望做怎样的修改。(Google 提到 Jules 可以直接嵌入 GitHub 中。)
Jules 对问题进行分析,给出了一个三步的编程解决方案,当用户点击同意后,模型开始自动编程,生成代码文件,这些代码可以一键被合并至用户原有的代码中。
游戏 Agent,则是看起来最有趣的一个演示。
Google 特意提到,Gemini 2.0 可以理解 Android 手机的屏幕分享和用户的语音,直接做到演示中的内容,不需要额外的后训练。
演示中,用户分享正在玩的手机屏,并用语音和 Agent 沟通,游戏 Agent 直接给出了接下来的最佳策略。
Google 表示目前正在和《部落冲突》、《海岛奇兵》等游戏做合作,帮助 Agent 理解游戏规则。同时 Agent 也会自己实时上网查找,来理解游戏规则给出最好的策略。
这个功能也可以说很炸裂了。对于纯策略型游戏,这个外挂可有点太厉害了——随着 AI 的进展,人脑对策略的理解恐怕没有办法和 AI 抗衡。或者说,或许只有最顶尖的大脑可以和 AI 相抗衡。
Gemini2.0 目前并没有对全部用户开放,Google 表示目前正在将 2.0 开放给开发者以及受信任的测试人员。这意味着以上的 Agent 功能,到用户真正能够使用,仍然有一段时间。不过此次演示仍然令人兴奋。
未来 Gemini 2.0 上线,Google 大概率也不会首发上述的 Agent 功能,而是将先将其融入 Gemini 和搜索功能。
Google 之前已经在探索将 AI 引入其搜索功能中。10 月,Google 曾经宣布,其搜索中的 AI 概述功能每月获得了 10 亿用户的使用。未来 Google 计划把 Gemini 2.0 的高级推理能力引入 AI 概述,以应对更复杂的话题和多步骤问题,包括高级数学方程式、多模态查询和编码。
此外,除了探索虚拟世界的智能体能力外,Google 还打算将 Gemini 2.0 的空间推理能力应用于机器人领域,尝试让 Agent 在现实世界中提供帮助。
02
Gemini Flash 常规更新
那么用户实际上能够马上使用的模型是什么?
答案是 Gemini 2.0 Flash。
作为 Google 大号模型蒸馏而来的小号模型,Gemini 2.0 Flash(对话优化版本)将成为 Google Gemini 中的默认使用模型。
Google 还推出了一项名为「深度研究」的新功能,该功能利用高级推理和长上下文能力作为研究助手,可以探索复杂主题并编制报告,今天在 Gemini 高级版中可用。
Gemini 2.0 Flash 的能力较上一代有明显提升,相当于上一代模型的 Pro 版本的能力。
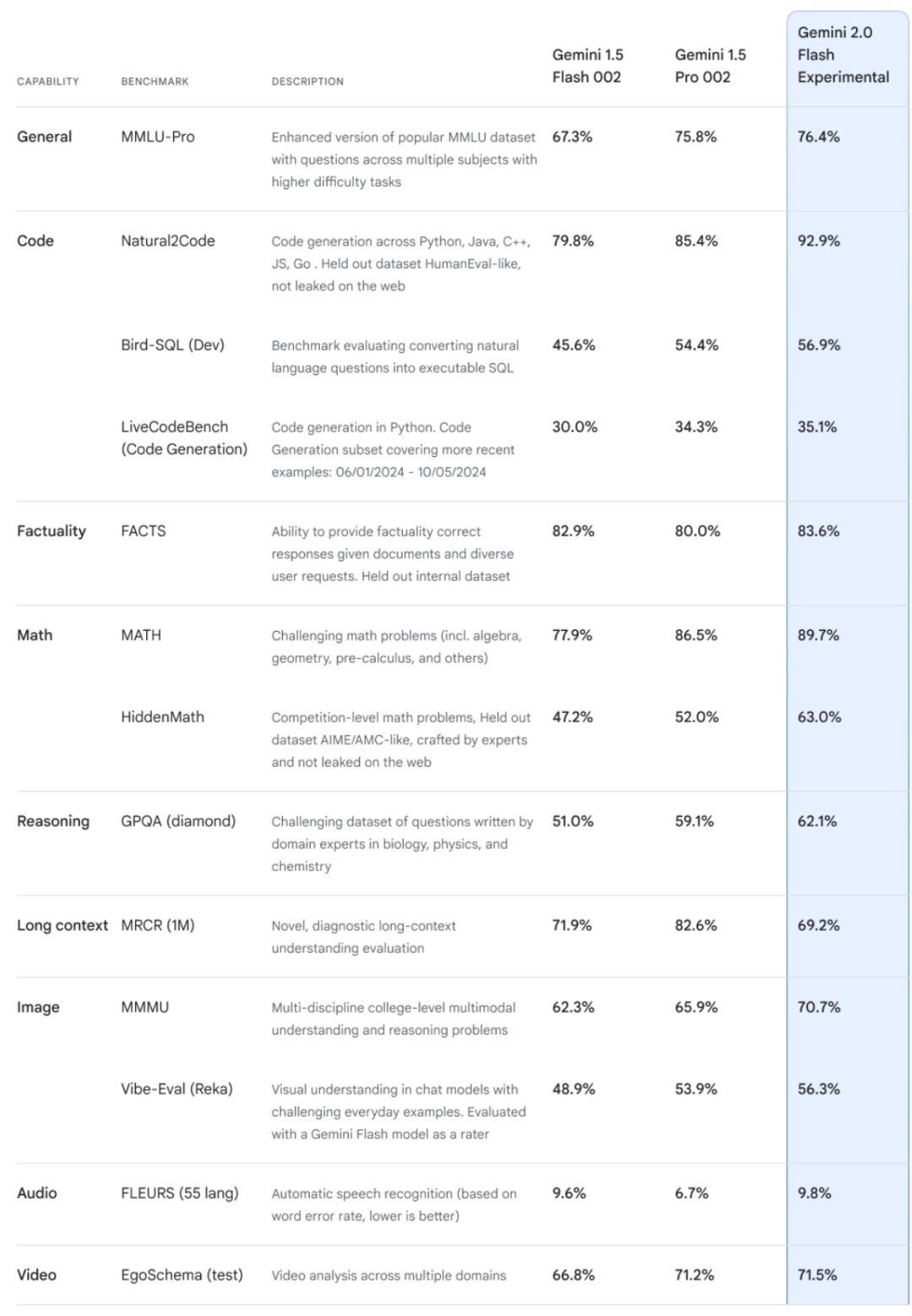
同时作为 2.0 模型家族的一员,Gemini 2.0 Flash 也支持支持图片、视频和音频等多模态输入,2.0 Flash 现在还可以支持多模态输出,例如可以直接生成图像与文本混合的内容,以及原生生成可控的多语言文本转语音 (TTS) 音频。它还可以原生调用 Google Search、代码执行以及第三方用户定义的函数等工具。
03
Project Astra:为 Google Glasses 准备的模型,拥有无限记忆?
Google 此次还重点介绍了 Project Astra,为其推出了以下改进:
·更流畅的对话:Project Astra 现在可以在多种语言和混合语言之间进行对话,并且能够更好地理解不同口音和生僻单词。
·新工具的使用:借助 Gemini 2.0,Project Astra 可以使用 Google Search、Google Lens 和 Google Maps,从而在日常生活中更好地发挥助手作用。
·更强的记忆力:我们增强了 Project Astra 的记忆能力,同时确保你可以掌控对话。现在,它最多可以记住长达 10 分钟的会话内容,并且可以回忆起过去与它进行的更多对话,以便为您提供更好的个性化服务。
·更低的延迟:借助新的流式处理技术和原生音频理解能力,该智能体能够以近于人类对话的延迟来理解语言。
Google Astra 是 Google 为了眼镜项目所做的前瞻项目。
从Meta 和 Ray-ban 的合作眼镜开始,国内外的不少公司,已经又在重新探索眼镜作为新一代智能硬件的潜力。
此次 Google 重大更新之一,是记忆能力。在外网采访中,DeepMind 的 CEO Demis Hassabis 表示,在 Gemini 1.5 时代,内部测试中,已经将其上下文窗口扩展到了 1000 万个 token 以上。目前已经模型几乎可以做到无限记忆。
但是代价就是速度。记忆越长,搜索相关记忆的成本越高,速度越低。不过 Demis Hassabis 认为,接下来相当短的时间内,我们将真正拥有无限长的上下文。
而这对于 Google 真正想做的助手而言是极其重要的。Demis Hassabis 形容未来世界:「你在电脑上使用这一助手,然后你走出家门,戴上眼镜,或者使用手机,它一直都在。它能够记住会话以及你想要做什么,真正个性化。我们人类无法记住所有事情,而AIvu u会记住所有事情,来给你以灵感和新的规划。」
04
Agent 时代已来?
从去年开始,就陆续有人指出 Agent 是 AI 发展的未来。
不过,在过去一年中,Agent 这个词的使用相对比较沉寂,甚至有时候被偷换概念当成 AI 应用来使用。
但是在今年年末,我们终于开始看到了相对可喜的进展。
首先是 Anthropic,推出电脑使用的 Agent 模式。
国内的智谱 AI,也推出了一个手机 Agent 替用户操作微信等 App 的的演示视频。
明年的 OpenAI 与苹果合作的 Apple Intelligence,目前仍然不确定全貌。很多人期待它将让许多用户第一次在手机上体会到简单的 Agent 功能到底能如何帮助我们提升生产力。
而现在我们又看到 Google 推出的浏览器 Agent 和安卓手机上的 Agent 使用演示。
Agent 技术依然面临诸多挑战。人们会担忧误操作可能带来的安全隐患,会担心隐私,会担心一系列风险。
但同时,对于普通用户而言,Agent 才是最具「AI 感」的技术。全自动的任务完成,像魔法一般,不需要任何技术背景,直接就能提升工作效率和使用体验。
Agent 能力的提升,也为一个新的智能硬件真正进入人们生活打下了基础——只有发出语音指令,眼镜能直接自动完成部分任务的时候,许多任务才会逐渐从手机转移至新的智能硬件终端。
或许真的如 Google AI Studio 的产品负责人 Logan Kilpatrick 今天早些时候所言:未来,是 Agent 的时代。
未经允许不得转载:滚雪球吧 - 让财富的雪球滚起来 » Google 深夜狙击 OpenAI:新 Agent 功能可以自己打开浏览器查资料了